先の記事で、LLMのアテンション機構の可視化を実施しました。そこからの続きで別の文について、可視化を試みてみます。モデルをGPT-2系の日本語モデルに変えて、『走れメロス』の冒頭の文に挑戦してみました。使用したのは以下の文になります。「メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。」
基本的なコードは先のコードですが、幾つか変わっています。実験はGoogle Colab上で行っています。
import torch
from transformers import GPT2Model, T5Tokenizer, GPT2LMHeadModel
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
model = GPT2LMHeadModel.from_pretrained("rinna/japanese-gpt2-medium", attn_implementation="eager")
text = "メロスは激怒した。必ず、かの邪智暴虐の王を除かなければならぬと決意した。メロスには政治がわからぬ。メロスは、村の牧人である。笛を吹き、羊と遊んで暮して来た。けれども邪悪に対しては、人一倍に敏感であった。"
tokens = tokenizer(text, return_tensors="pt")
# トークンIDを対応する単語へ変換
tokens_list = tokenizer.convert_ids_to_tokens(tokens["input_ids"][0].tolist())
# 最後の層、最初のAttentionヘッドを取得
layer_idx = -1
head_idx = 0
attention_matrix = attentions[layer_idx][0, head_idx].cpu().numpy()
# 左上1/4部分を切り取る
quarter_size = attention_matrix.shape[0] // 2 # 行列サイズの1/2を計算
subset_matrix = attention_matrix[:quarter_size, :quarter_size] # 左上1/4部分を抽出
# 対応するトークンのリストも切り取る
subset_tokens = tokens_list[:quarter_size]
# ヒートマップを描画
plt.figure(figsize=(8, 8))
sns.heatmap(subset_matrix, cmap="viridis", xticklabels=subset_tokens, yticklabels=subset_tokens)
plt.xlabel("Attention対象")
plt.ylabel("Attention元")
plt.title("左斜め上1/4のAttentionマップ拡大表示")
plt.xticks(rotation=90, fontsize=8)
plt.yticks(fontsize=8)
plt.show()
可視化した結果が以下になります。アテンションマップの隅1/4を拡大しています。
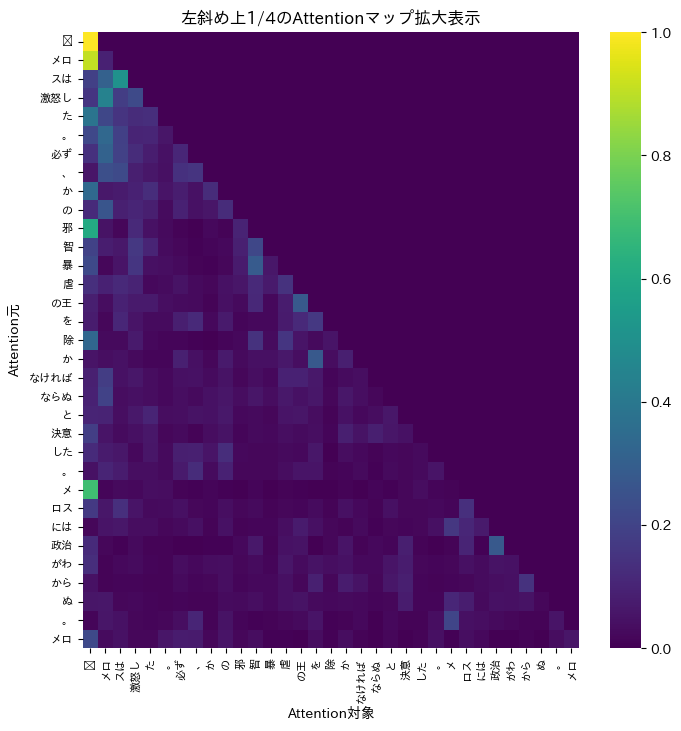
ここから言えることは、恐らく、メロスの単語が辞書にないためだと思いますが、メロスの挙動は不安定です。その結果、周囲の文脈から何を意味しているか推測している可能性があります。また、主語「メロス」と「邪」のようなワードに注意が向いているようです。「邪智暴虐」という表現が特徴的ですから、AIがそのフレーズを重要だととらえている可能性があります。また、文のイメージがネガティブというのも影響している可能性があります。また、除にも注意が向いているので、「除かなければならぬ」などの文脈に注意が流れている可能性があります。