“採血データを使った心不全予測"のコンペに参加したので、解法を示します。まず、基本的に、2つの分類の予測問題は元々慣れていたので基本的なフレームとしては以下の通りです。
- 探索的データ分析
- ベースラインモデルの作成
- 予測モデルの作成
探索的データ分析
まず、最初にデータを一応概観してみました。 発売中の技術同人誌 “Pythonによる探索的データ分析クックブック“でも触れている、ydata-profilingを使用しています。
import os
import sys
import pandas as pd
import polars as pl
import pyarrow as pa
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from ydata_profiling import ProfileReport
train_df = pd.read_csv("../data/train.csv")
test_df = pd.read_csv("../data/test.csv")
profile = ProfileReport(train_df, title="Heart Failure Report")
profile.to_file("../profile/heart_failure_report.html")
ベースラインモデルの作成
基本線となるベースラインモデルを作成しました。ベースラインモデルは文字通りベースラインモデルなので、複雑なものは避けるのがセオリーです。今回は二つの分類をするタイプなので、一般化線形回帰でロジスティック回帰に持ち込むのを基本としました。また、stepwiseなどの容易さから、一旦、Rでモデリングを進めました。 コードとしては以下のシンプルきわまるものです。
require(dplyr)
require(readr)
require(ggplot2)
require(pROC)
train.df <- read.csv("../data/train.csv")
test.df <- read.csv("../data/test.csv")
train.df <- train.df %>%
mutate(
anaemia = as.factor(anaemia),
diabetes = as.factor(diabetes),
high_blood_pressure = as.factor(high_blood_pressure),
sex = as.factor(sex),
smoking = as.factor(smoking),
target = as.factor(target)
)
require(MASS)
model <- glm(formula = target ~ age + anaemia + creatinine_phosphokinase + diabetes + ejection_fraction + high_blood_pressure + platelets + serum_creatinine + serum_sodium + sex + smoking + time, data = train.df, family = binomial)
model.opt <- stepAIC(model)
pred.df <- predict(model.opt, train.df, type = "response")
roc_curve <- roc(train.df$target, pred.df)
auc_value <- auc(roc_curve)
ar_value <- (auc_value - 0.5) * 2
print(paste("AR値:", ar_value))
cat("Length of Cumulative_Percentage:", length(seq(0, 1, length.out = nrow(train.df))), "\n")
cat("Length of Predicted_Positive:", length(sort(pred.df, decreasing = TRUE)), "\n")
cat("Length of Actual_Positive:", length(sort(as.numeric(train.df$target), decreasing = TRUE)), "\n")
sorted_predictions <- sort(pred.df, decreasing = TRUE) # 予測確率を降順に
sorted_targets <- sort(as.numeric(as.character(train.df$target)), decreasing = TRUE) # 実ターゲットを降順に
n <- min(length(sorted_predictions), length(sorted_targets))
cumulative_data <- data.frame(
Cumulative_Percentage = seq(0, 1, length.out = n),
Predicted_Positive = cumsum(sorted_predictions[1:n]),
Actual_Positive = cumsum(sorted_targets[1:n])
)
ggplot(cumulative_data, aes(x = Cumulative_Percentage)) +
geom_line(aes(y = Predicted_Positive, color = "モデル予測")) +
geom_line(aes(y = Actual_Positive, color = "実データ")) +
scale_y_continuous(name = "累積正例率", limits = c(0, max(cumulative_data$Predicted_Positive, cumulative_data$Actual_Positive))) +
scale_x_continuous(name = "累積パーセンテージ", limits = c(0, 1)) +
labs(title = "CAP図") +
theme_minimal()
最終的には以下のCAP図になりました、
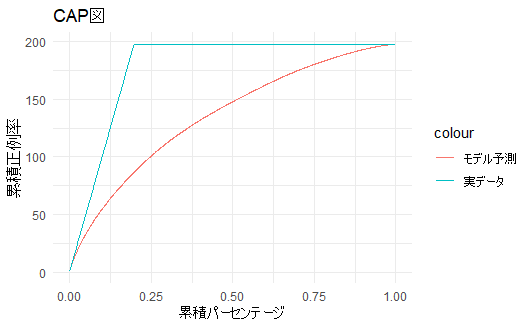
AR値としては高すぎず低すぎず、モデルとしては思ったものになったと判断、そのままモデル化を進めました。
基盤モデルの構築
基盤モデルとしては、今回はH2Oによる、AutoMLを選択しました。時間もあんまり欠けたくなかったし、これで何処まで行けるかというのもあった。 コードとしては以下のものです。
import os
import sys
import pandas as pd
import polars as pl
import pyarrow as pa
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import h2o
def plot_cap_curve(y_true, y_pred_proba, model_name="Model"):
"""
CAP (Cumulative Accuracy Profile) 曲線を描画する。
Parameters:
y_true (array-like): 実際のラベル (0または1)
y_pred_proba (array-like): モデルの予測確率 (1に属する確率)
model_name (str): モデル名(プロットのラベル用)
"""
# 実データを予測確率でソート
total_positives = np.sum(y_true)
total_samples = len(y_true)
sorted_indices = np.argsort(-y_pred_proba) # 降順でソート
y_true_sorted = np.array(y_true)[sorted_indices]
# 累積で正例を取得
cum_positives = np.cumsum(y_true_sorted)
# x軸 (サンプルの割合)
x = np.arange(1, total_samples + 1) / total_samples
# モデルの累積曲線 (y軸: 累積ポジティブ率)
model_curve = cum_positives / total_positives
# 完全ランダムモデル (対角線)
random_curve = x
# 完璧なモデルの仮想曲線
perfect_curve = np.concatenate([
np.linspace(0, 1, int(total_positives)), # 正例の割合
np.ones(total_samples - int(total_positives)) # 残りは1
])
# プロット
plt.figure(figsize=(8, 6))
plt.plot(x, model_curve, label=f"{model_name} (CAP)", color='b', linewidth=2)
plt.plot(x, random_curve, label="Random Model", linestyle="--", color="red")
plt.plot(np.linspace(0, 1, total_samples), perfect_curve, label="Perfect Model", linestyle="--", color="green")
plt.xlabel("Fraction of Samples")
plt.ylabel("Cumulative Positive Rate")
plt.title("CAP Curve")
plt.legend(loc="lower right")
plt.grid()
plt.show()
def calculate_ar(y_true, y_pred_proba):
"""
AR値を計算する関数。
Parameters:
y_true (array-like): 実際のラベル (0または1)
y_pred_proba (array-like): モデルの予測確率 (1に属する確率)
Returns:
float: AR値
"""
# 実データを予測確率でソート
sorted_indices = np.argsort(-y_pred_proba) # 降順でソート
y_true_sorted = np.array(y_true)[sorted_indices]
# 累積正例を計算
total_positives = np.sum(y_true)
total_samples = len(y_true)
cum_positives = np.cumsum(y_true_sorted)
# x軸 (サンプルの割合)
x = np.arange(1, total_samples + 1) / total_samples
# モデルの累積面積 (Model Area)
model_area = np.trapz(cum_positives / total_positives, x)
# ランダムモデルの累積面積 (Random Area)
random_area = 0.5 # ランダムモデルは正方形の対角線下の面積
# 完璧なモデルの累積面積 (Perfect Area)
perfect_area = 1.0 # 完璧なモデルは全てのポジティブを最初に取得するため面積は1.0
# AR値を計算
ar_value = (model_area - random_area) / (perfect_area - random_area)
return ar_value
train_df = pl.read_csv("../data/train.csv")
test_df = pl.read_csv("../data/test.csv")
train_df_pd = train_df.to_pandas()
test_df_pd = test_df.to_pandas()
h2o.init()
train_h2o = h2o.H2OFrame(train_df_pd)
test_h2o = h2o.H2OFrame(test_df_pd)
train_h2o["anaemia"] = train_h2o["anaemia"].asfactor()
train_h2o["diabetes"] = train_h2o["diabetes"].asfactor()
train_h2o["high_blood_pressure"] = train_h2o["high_blood_pressure"].asfactor()
train_h2o["sex"] = train_h2o["sex"].asfactor()
train_h2o["smoking"] = train_h2o["smoking"].asfactor()
train_h2o["target"] = train_h2o["target"].asfactor()
train_h2o.describe()
columns = train_h2o.columns
columns.remove("id")
columns.remove("target")
y = "target"
X = columns
print("X:", X)
print("y:", y)
aml = h2o.automl.H2OAutoML(max_models=30, nfolds=5, balance_classes=True, preprocessing=['target_encoding'], sort_metric='AUCPR', stopping_metric="AUCPR")
aml.train(x=X, y=y, training_frame=train_h2o)
aml.leaderboard.head(10)
leader = aml.leader
preds_h2o = leader.predict(train_h2o)
preds_h2o.head()
preds_df = preds_h2o.as_data_frame()
preds = preds_df["p1"].values
true_y = train_df["target"].to_numpy()
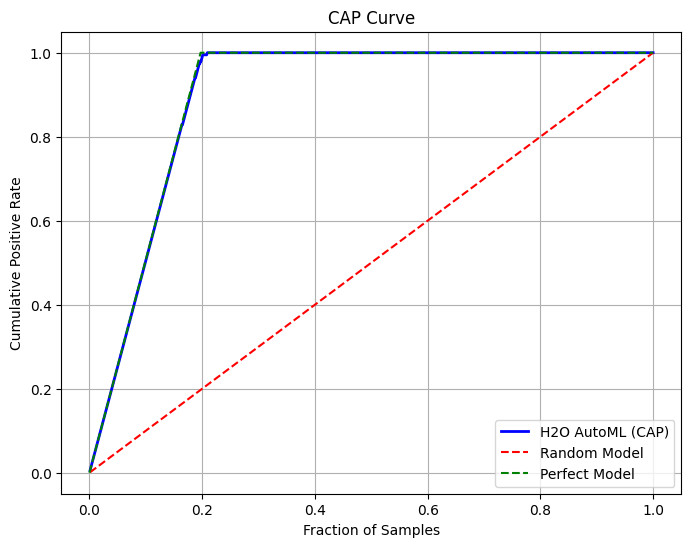
plot_cap_curve(true_y, preds, model_name="LightGBM")
print(calculate_ar(true_y, preds))
final_predict = leader.predict(test_h2o)
final_predict_df = final_predict.as_data_frame()
final_y = final_predict_df["predict"]
submission = pd.concat([test_df.to_pandas()["id"], final_y], axis=1)
h2o.cluster().shutdown()
submission.head()
最終的なCAP図としては以下のものです。
CAP図としては、パーフェクトモデルと言って、ほぼ近しいものです。この時点で、これ以上のモデリングは意味がないと判断しました。ほぼ形状としてパーフェクトな以上、 モデリングで出来ることはほぼないと考えました。よってこれ以降の精度向上は、閾値のチューンに的を絞りました。 H2Oのデフォルトの閾値はかなり1の側に倒れており、これをチューンすることにしました。
閾値のチューン
閾値のチューンはまず、以下のようなコードを何回か走らせています。今回掲載しているのは最終コードですが、閾値の探索範囲は最初、0-1の間で試し、その後、アウトプットを見ながら調節しています。 閾値のチューンはOptunaを用いて行っています。最終的に、0.49 - 0.496の間でベストな閾値を探しています。この閾値のチューンは重要でした。実際に、100位台から一気に、30位台にジャンプアップした部分はここです。
import os
import sys
import pandas as pd
import polars as pl
import pyarrow as pa
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import h2o
import optuna
def plot_cap_curve(y_true, y_pred_proba, model_name="Model"):
"""
CAP (Cumulative Accuracy Profile) 曲線を描画する。
Parameters:
y_true (array-like): 実際のラベル (0または1)
y_pred_proba (array-like): モデルの予測確率 (1に属する確率)
model_name (str): モデル名(プロットのラベル用)
"""
# 実データを予測確率でソート
total_positives = np.sum(y_true)
total_samples = len(y_true)
sorted_indices = np.argsort(-y_pred_proba) # 降順でソート
y_true_sorted = np.array(y_true)[sorted_indices]
# 累積で正例を取得
cum_positives = np.cumsum(y_true_sorted)
# x軸 (サンプルの割合)
x = np.arange(1, total_samples + 1) / total_samples
# モデルの累積曲線 (y軸: 累積ポジティブ率)
model_curve = cum_positives / total_positives
# 完全ランダムモデル (対角線)
random_curve = x
# 完璧なモデルの仮想曲線
perfect_curve = np.concatenate([
np.linspace(0, 1, int(total_positives)), # 正例の割合
np.ones(total_samples - int(total_positives)) # 残りは1
])
# プロット
plt.figure(figsize=(8, 6))
plt.plot(x, model_curve, label=f"{model_name} (CAP)", color='b', linewidth=2)
plt.plot(x, random_curve, label="Random Model", linestyle="--", color="red")
plt.plot(np.linspace(0, 1, total_samples), perfect_curve, label="Perfect Model", linestyle="--", color="green")
plt.xlabel("Fraction of Samples")
plt.ylabel("Cumulative Positive Rate")
plt.title("CAP Curve")
plt.legend(loc="lower right")
plt.grid()
plt.show()
def calculate_ar(y_true, y_pred_proba):
"""
AR値を計算する関数。
Parameters:
y_true (array-like): 実際のラベル (0または1)
y_pred_proba (array-like): モデルの予測確率 (1に属する確率)
Returns:
float: AR値
"""
# 実データを予測確率でソート
sorted_indices = np.argsort(-y_pred_proba) # 降順でソート
y_true_sorted = np.array(y_true)[sorted_indices]
# 累積正例を計算
total_positives = np.sum(y_true)
total_samples = len(y_true)
cum_positives = np.cumsum(y_true_sorted)
# x軸 (サンプルの割合)
x = np.arange(1, total_samples + 1) / total_samples
# モデルの累積面積 (Model Area)
model_area = np.trapz(cum_positives / total_positives, x)
# ランダムモデルの累積面積 (Random Area)
random_area = 0.5 # ランダムモデルは正方形の対角線下の面積
# 完璧なモデルの累積面積 (Perfect Area)
perfect_area = 1.0 # 完璧なモデルは全てのポジティブを最初に取得するため面積は1.0
# AR値を計算
ar_value = (model_area - random_area) / (perfect_area - random_area)
return ar_value
train_df = pl.read_csv("drive/MyDrive/Signate/HeartFailure/train.csv")
test_df = pl.read_csv("drive/MyDrive/Signate/HeartFailure/test.csv")
train_df_pd = train_df.to_pandas()
test_df_pd = test_df.to_pandas()
h2o.init()
train_h2o = h2o.H2OFrame(train_df_pd)
test_h2o = h2o.H2OFrame(test_df_pd)
train_h2o["anaemia"] = train_h2o["anaemia"].asfactor()
train_h2o["diabetes"] = train_h2o["diabetes"].asfactor()
train_h2o["high_blood_pressure"] = train_h2o["high_blood_pressure"].asfactor()
train_h2o["sex"] = train_h2o["sex"].asfactor()
train_h2o["smoking"] = train_h2o["smoking"].asfactor()
train_h2o["target"] = train_h2o["target"].asfactor()
train_h2o.describe()
columns = train_h2o.columns
columns.remove("id")
columns.remove("target")
y = "target"
X = columns
aml = h2o.automl.H2OAutoML(max_models=30, nfolds=5, balance_classes=True, preprocessing=['target_encoding'], sort_metric='AUCPR', stopping_metric="AUCPR")
aml.train(x=X, y=y, training_frame=train_h2o)
aml.leaderboard.head(10)
leader = aml.leader
preds_h2o = leader.predict(train_h2o)
preds_h2o.head()
preds_df = preds_h2o.as_data_frame()
preds = preds_df["p1"].values
true_y = train_df["target"].to_numpy()
plot_cap_curve(true_y, preds, model_name="H2O AutoML")
print(calculate_ar(true_y, preds))
h2o.save_model(leader, 'drive/MyDrive/Signate/HeartFailure/Models/20250420')
preds_df.head()
preds_df.shape
train_df.head()
def objective(trial):
threshold = trial.suggest_float("threshold", 0.49, 0.496) # 閾値の探索範囲
preds_binary = (np.array(preds_df["p1"]) >= threshold).astype(int) # 予測結果を整数型(int)に変換
target_binary = np.array(train_df["target"]).astype(int) # 正解ラベルを整数型(int)に変換
accuracy = (preds_binary == target_binary).mean() # 精度の計算
return accuracy
study = optuna.create_study(direction="maximize") # 精度を最大化
study.optimize(objective, n_trials=2000) # 試行回数2000回で探索
study.best_trial
best_threshold = study.best_trial.params["threshold"]
final_predict = leader.predict(test_h2o)
final_predict_df = final_predict.as_data_frame()
final_predict_df.head()
# 最適閾値を適用し、2値分類を実施
final_predict_df["predicted_label"] = (final_predict_df["p1"] >= best_threshold).astype(int)
# 結果を確認
print(final_predict_df.head())
# H2O標準の結果と閾値適用後の結果を比較
final_predict_df["difference"] = final_predict_df["predict"] != final_predict_df["predicted_label"]
# 相違のあるデータを抽出
differences_df = final_predict_df[final_predict_df["difference"]]
# 結果の概要を表示
print(f"異なる予測の件数: {differences_df.shape[0]}")
print(differences_df.head())
final_y = final_predict_df["predicted_label"]
submission = pd.concat([test_df.to_pandas()["id"], final_y], axis=1)
h2o.cluster().shutdown()
submission.to_csv('drive/MyDrive/Signate/HeartFailure/submission.csv', index=False, header=False)
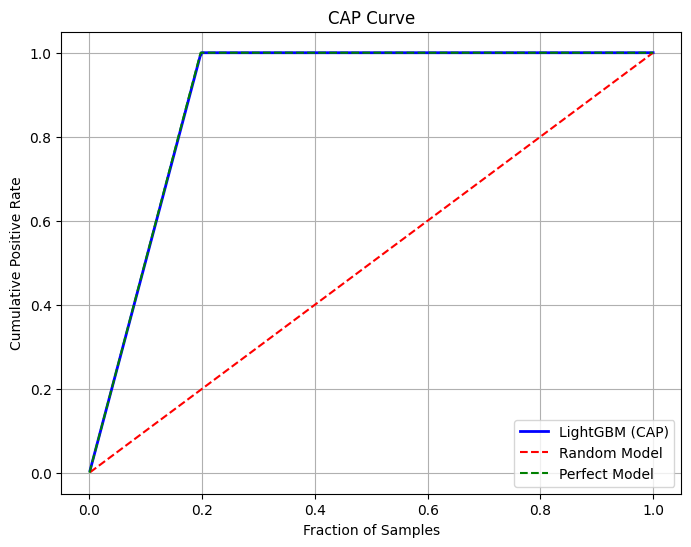
最終的にSubmissionした時のCAP図は以下のものです。ほぼほぼパーフェクトモデルそのものです。